
你的購物車目前是空的!

本篇文章將介紹 Spark(https://spark.apache.org/) 和 Databricks(https://www.databricks.com/) 兩大數據分析工具,探討 Databricks 為何成為大數據分析的熱門平台。透過了解其特性和優勢,資料分析師可以更有效地進行數據處理和分析工作。(本文沒有收到任何來自 Spark 和 Databticks 的業配 XD)
資料分析師在大數據環境的痛點
在資料量小、團隊小的時候,資料分析師習慣在自己的本機上做事,靠自己用個幾個 notebook 搞定所有資料分析的流程。但是這樣的做法在來到大數據、大團隊環境後,會發生幾個困難:
- 複雜的數據工程:傳統方法需要手動管理數據管道,從數據提取、清洗到加載過程,都需要花費大量的時間和精力。
- 缺乏協作工具:在分散的工具環境中,跨團隊協作變得困難。數據工程師、數據科學家和業務分析師之間的溝通往往需要通過多種工具和手動分享結果。
- 性能和擴展性問題:本地化系統和傳統數據庫在處理大規模數據時常常面臨性能瓶頸。
- 整合機器學習和 AI 的困難:在傳統環境中,將機器學習和 AI 模型集成到數據分析流程中需要大量的手動工作和專業知識。
- 雲端整合和靈活性:許多傳統方法缺乏與雲服務的無縫整合,導致資源管理和擴展變得困難。
以下我們要介紹的兩個工具,就是為了解決這些痛點而生。
Spark 和 Databricks
Apache Spark 是一個強大的開源分布式計算系統,專為處理和分析大數據而設計。它提供高效的計算速度,並且能夠處理多種數據處理任務,包括批處理、即時流處理和機器學習。
Databricks 是一個基於雲端的數據工程和數據科學平台,由 Spark 的創始人創立。它將 Spark 的強大功能與雲端的靈活性結合在一起,為用戶提供一個全面的數據分析環境。
Spark 的特點
Apache Spark 是一個強大的開源分布式計算框架,其特點包括:
- 高速處理:Spark 使用 in-memory 的計算技術,比傳統的 MapReduce 快10到100倍,適合處理大規模數據集和實時數據分析。
- 多用途數據處理:Spark 支持多種資料處理任務,包括批次(Batch)處理、即時串流(Streaming)處理、互動查詢(Spark SQL)和機器學習,提供一個統一的計算框架。
- 易用的 API:Spark 提供易於使用的 API,支持多種編程語言,包括 Java、Scala、Python 和 R,使開發者能夠使用自己熟悉的語言進行開發。
- 擴展性強:Spark 能夠輕鬆擴展到數千個節點,適合處理從 GB 到 PB 級別的數據,具備高度的擴展性和彈性。
- 與 Hadoop 生態系統集成:Spark 可以與 Hadoop 生態系統中的 HDFS、HBase 和 YARN 等組件無縫集成,方便現有 Hadoop 用戶進行數據處理和分析。也可以和主流雲端系統整合,例如 AWS, GCP, Azure,可以存儲這些雲端平台上的資料。
這些特點使得 Apache Spark 成為大數據處理和分析的理想選擇,幫助資料分析師快速、高效地處理和分析大規模數據。更多的好處我們放在:PySpark-資料分析師和資料科學家的必備技能。
Databricks 的特點
Databricks 平台提供一個一體化的資料分析解決方案,結合了資料工程、數據科學和機器學習的功能。其主要特點包括:
- 自動化集群管理:Databricks 提供自動化的集群管理功能,使得用戶可以輕鬆地配置和管理計算資源,實現自動擴展和高可用性。
- 協作環境:內建的協作筆記本(Collaborative Notebooks)允許團隊成員實時協作,分享代碼和結果,促進跨部門的協作與知識共享。
- 多語言支持:支持多種編程語言,包括 Python(PySpark)、R、SQL 和 Scala,使得用戶可以使用自己熟悉的語言進行數據分析和建模。
- 高效的數據處理:利用 Spark 的內存計算技術,Databricks 提供快速且高效的數據處理能力,適合處理大規模數據集和複雜的數據運算。
- 安全性和治理:提供企業級的安全性和數據治理功能,包括顆粒度的權限控制、活動活動紀錄和資料加密,確保數據的安全性和合規性。
- 雲端整合:與主要的雲服務提供商(如 AWS、Azure、Google Cloud)無縫整合,提供靈活的雲端部署選項和資源管理,支持混合雲和多雲策略。
這些特點使得 Databricks 成為大數據分析的理想工具,能夠滿足不同規模企業的數據需求,提升數據處理和分析的效率。
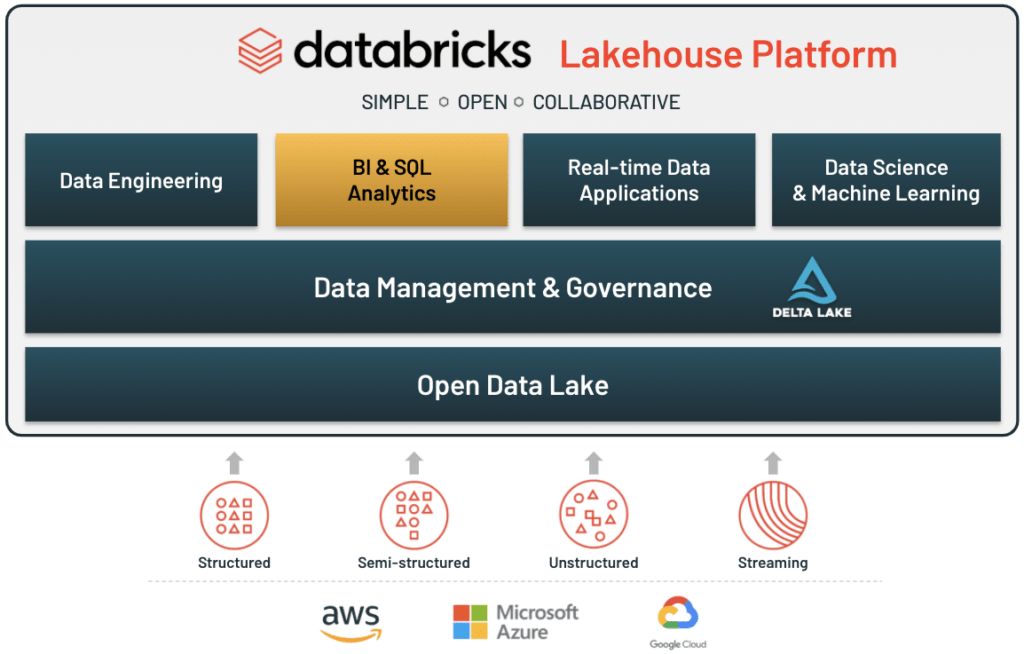
使用 Databricks 進行大數據分析的優勢
簡化的資料工程流程
傳統方法需要手動管理資料管線。從數據提取、清洗到加載過程,都需要花費大量的時間和精力。Databricks 提供了直觀的用戶界面和強大的工具,簡化了數據提取、轉換和加載(ETL)過程。這使得資料分析師可以更快地準備和處理數據。相關服務包括 Databricks Delta Lake,這是一個高度可靠的數據存儲層,可以確保數據的一致性和可用性。
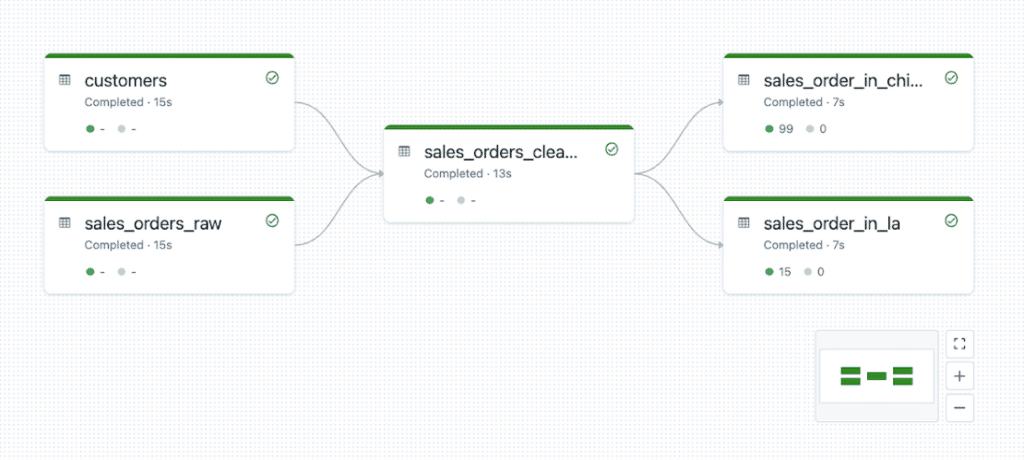
高效的協作環境
在分散的工具環境中,跨團隊協作變得困難。數據工程師、資料科學家和分析師之間的溝通往往需要通過多種工具和手動分享結果。Databricks 支持跨團隊協作,使資料工程師、資料科學家和業務分析師能夠在同一平台上共同工作,提高工作效率和準確性。其 Collaborative Notebooks 功能允許多個用戶即時協作,分享代碼和結果,促進團隊間的知識共享。
可擴展性和性能
在單機系統和傳統資料庫在處理大規模資料時常常面臨性能瓶頸。Databricks 可以自動擴展以處理大規模資料集,並且利用 Spark 的內存計算優勢,提供快速的數據處理能力。 Databricks Runtime 是一個高度優化的執行環境,專為提升 Spark 性能而設計,確保高效的數據處理。同時支援各種資料分析師常用的語言,不管是 R 或 Python。
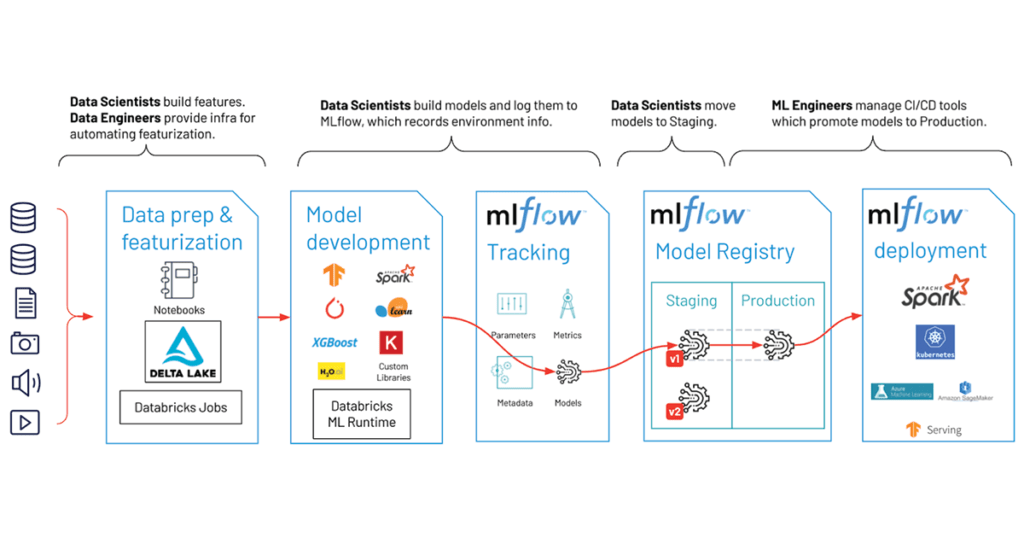
整合機器學習和 AI
在傳統環境中,將機器學習和 AI 模型結合到資料分析流程中需要大量的手動工作和專業知識。Databricks 支持機器學習和 AI 模型的開發和部署,Databricks Machine Learning 平台提供了豐富的工具和庫,幫助用戶構建、訓練和部署機器學習模型。
雲原生的靈活性
作為一個雲端服務,Databricks 能夠與各大雲服務提供商(如 AWS、Azure、Google Cloud)無縫整合,提供靈活的部署選項和資源管理。相關服務包括 Azure Databricks、AWS Databricks、以及 Google Cloud Databricks。

小結
這些服務和功能使 Databricks 成為大數據分析的理想工具,能夠滿足不同規模企業的資料需求,提升資料處理和分析的效率。同時也簡化了資料分析上手的難度,讓資料分析師可以輕易地將自己的技術知識轉移到 Databricks 上。
參考資料
- What is Databricks? – Databricks
- Databricks and Spark on AWS – AWS Blog
- What is Azure Databricks? – Microsoft Azure
- The Role of Apache Spark and Databricks in Big Data – IBM Developer
- Benefits of Databricks for Real-Time Analytics – Cloudera Blog
相關文章


最新活動
-
特價商品
 軟體工程師跨國遠端攻略-從履歷到面試一步到位!$239.00 – $639.00
軟體工程師跨國遠端攻略-從履歷到面試一步到位!$239.00 – $639.00
在〈資料分析師處理大數據的救星: Spark 和 Databricks〉中有 5 則留言
mirtazapine 15 mg tablet
mirtazapine 15 mg tablet
mobic 7.5 mg tablet
mobic 7.5 mg tablet
ivermectin topical
ivermectin topical
lasix 40 mg tablet
lasix 40 mg tablet
fluconazole 150 mg tablet
fluconazole 150 mg tablet
發佈留言